Let’s consider smartphones for a moment – have you noticed the sharp trajectory of human-like features they’re packing and how they’ve been able to do so many things on their own lately? How does the face recognition method work? How does it differentiate your face from other people’s faces? There is a single answer to all these questions – Artificial Intelligence, or more specifically, ensemble learning in most cases.
Don’t know how ensemble learning techniques work? Well, don’t worry, you’re in the right place. Today in this article, we will be exploring different ensemble learning techniques – both traditional and latest. Also, we’ll go through the mechanisms behind them so that if you’re new to them, you will have a clear idea of how they work.
What is Ensemble Learning?
Ensemble learning is a machine learning technique that combines the results of predictions made by multiple models, aka weak learners, to create a strong learner that helps make informed decisions. The idea behind ensemble learning is that a group of weak learners, when combined, can form a strong learner that outperforms the individual models.
For example, let’s say you want to predict the outcome of a football match. You can create multiple models, each using different features like the team’s past performance, player stats, and weather conditions. Individually, these models may not be accurate enough. However, if you combine their predictions using an ensemble learning technique like a voting classifier, the overall accuracy may increase significantly.
How to Use Ensemble Learning Techniques?
If you’re now familiar with ensemble learning, you’re now probably wondering how it works. The typical ensemble learning process includes 5 steps, comprising model selection, model training, combining predictions (ensembling), evaluation, and tuning. Here is a simple step-by-step breakdown of how you can use different ensemble methods:

Step 1: Choose the models that you want to work with. This is probably the most important step to take, as it has to be done while keeping your use case in consideration. There is a wide range of options that you could choose from, e.g., decision trees, random forests, neural networks, etc.
Step 2: Train the models you selected using your training dataset through different algorithms and different subsets of data. This procedure ensures that each model learns from a different perspective, capturing different patterns and signals from the data.
Step 3: This is the main step – combine the results of the models that you’ve trained using some particular techniques (we’ll explore these further in the article). For example, let’s assume you want to predict whether a customer will buy a product based on their age, gender, and past purchase history. Now you could train three different models to predict the likelihood of the customer making a purchase, e.g., a decision tree, a logistic regression model, and a neural network, enabling you to create a more accurate and robust learner.
Step 4: Evaluate your results. Do the combined results match your expected results? If not, then what could be fixed? This step can be done with the help of a validation dataset that checks how the final model is better than the initial one.
Step 5: Tune your results. This is where you work on the weak points of your final model to make a robust learner by reassigning the weights to different components or adding/removing some layers.
By following these steps closely, you can create a more accurate and robust machine learning model using ensemble learning techniques.
Some Popular Ensemble Learning Techniques?
Let’s dive into some of the most commonly used ensemble techniques these days. These techniques can be broadly categorized into two groups, i.e., simple and complex ensemble learning techniques. The complexity of a method depends on the number and types of models used, the kind of data used, and the required accuracy of the final results.
Simple Ensemble Techniques
Simple ensemble learning techniques usually require fewer models, and their approach to making predictions is more straightforward. Let’s take a closer look at the two main types of simple ensemble learning methods:
- Max Voting
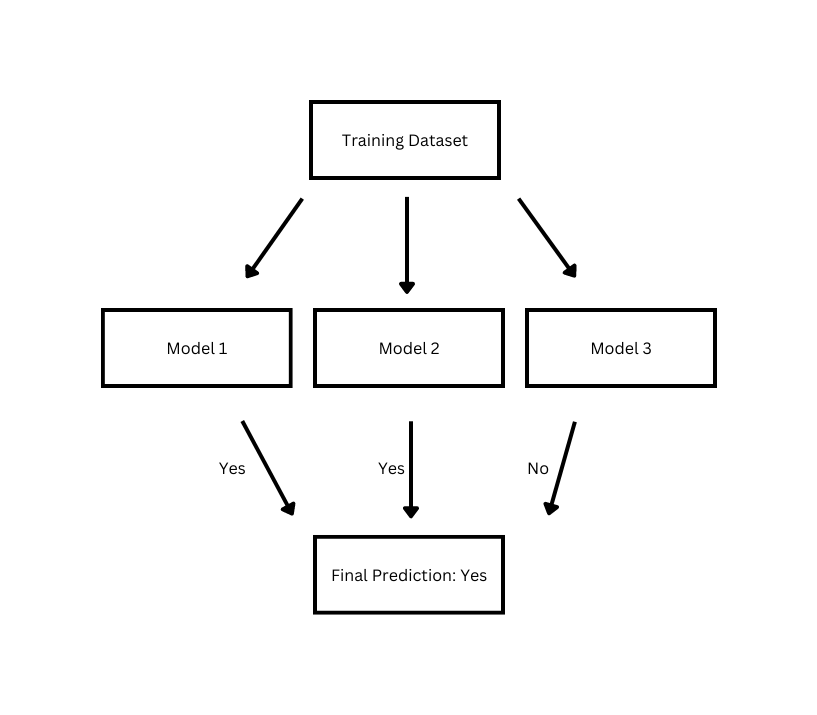
The max voting method is ideal for binary classification problems and is simple to implement. It makes the final predictions by checking which class got the most votes and so provides you with the most common answer from multiple options. It’s heavily used in binary classification problems; however, if you are working with a highly correlated dataset, it may not be able to give you the most accurate results.
- Averaging and Weighted Averaging
As the name would suggest, the averaging process takes the average of the output from every model, i.e., adding the answers from every model and dividing it by the number of models. If you notice that an individual model is performing better than the rest of the model, you can assign more weight to its answer since it’s more reliable than the others.
Taking the average of the individual predictions after giving weight is called the weighted average. Averaging is super easy to use for beginners and delivers decent results as well, but it might not be the best option for dealing with complex datasets.
Complex Techniques
When working with high-dimensional data or too many models, the simple ensemble techniques that we explored above don’t work that well. So, we need to resort to using complex ensemble learning techniques to obtain accurate results. Let’s explore the three most popular ensemble learning techniques below, namely bagging, boosting, and stacking.
- Bagging
Bagging stands for Bootstrap Aggregating and works by feeding all the models to different subsets of the same training dataset. Once a subset has been selected, it is placed back into the original dataset and can be chosen again by the model. Every model produces different results; the final results can be averaged by assigning weights. Not only does this method reduce the variance in the results, but it also reduces the risk of overfitting.
This more straightforward method uses models like decision trees or neural networks because they are more prone to overfitting. The following are some popular bagging techniques:
- Boosting
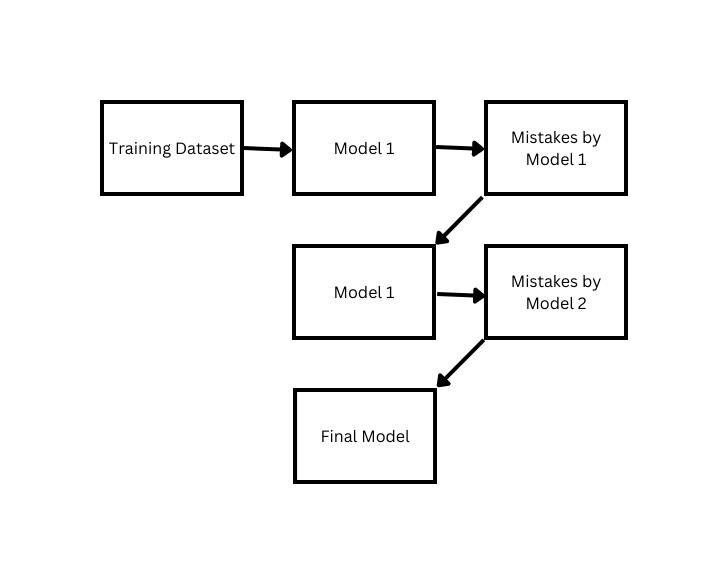
Boosting is also similar to bagging, except that in boosting, multiple models are trained iteratively, whereas bagging trains the models simultaneously. Here’s how boosting works – Once a model has been analyzed against the training data, its errors are assigned more weight and passed on to the second model. The second model, in turn, must ensure that it avoids making the errors made by the previous model. This is done because instead of working on problems already solved, the model can work on those more complicated examples where it needs to improve.
Boosting is unarguably the most popular ensemble learning technique out there and is used in most ML competitions and state-of-the-art solutions. It has several types, and they all have proven extremely effective in various applications. The most used boosting algorithms are:
- LGBM (Light Gradient Boost)
- GBM (Gradient Boost)
- XGBM (Extreme Gradient Boost)
- CatBoost (Category Boosting)
- Ada Boost (Adaptive Boosting)
- Stacking
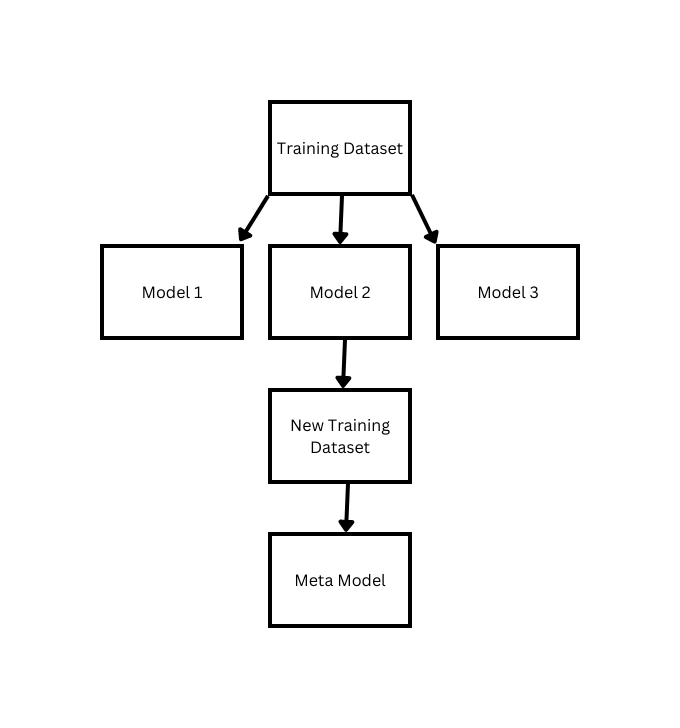
When it comes to stacking, it’s significantly different than bagging and boosting. Stacking involves every model being trained using a different algorithm or hyperparameter configuration. The results from all these models are combined to make a new dataset to prepare a meta-model to make the final predictions.
The predictions made by this technique are exceptionally reliable since it collects the data by different methods, therefore, making the projections far more reliable than any individual model. Nevertheless, this technique is expensive to compute and requires significant data since the models are stacked on top of each other.
-

Bagging vs Boosting vs Stacking
-

What is Ensemble Learning? Advantages and Disadvantages of Different Ensemble Models
-

How AI can be used in Decision making
To Sum Up
Ensemble learning techniques are powerful tools that help make accurate decisions using machine learning. Some simple methods like max voting and averaging are much easier to implement and can be used if you’re working with smaller datasets and simpler situations. However, when dealing with complex scenarios, you might need a little more sophisticated methods, the likes of which we’ve covered in our second section.
So, the choice between what type of technique you want to work with depends on the requirements of the problem at hand. Once you’ve done enough research, you can identify when to use which algorithm.
