In a world where we’re surrounded with data on all four sides, artificial intelligence is one of the most growing fields, putting all that data to good use. If you take a good look around, from Netflix’s recommendation systems to WhatsApp’s emoji suggestions, AI is everywhere.
Within AI, there’s a sub-field called deep learning, which includes using neural networks to learn complex patterns and structures present in data, using the same model as used in human brains – neurons. However, there are many different types of neural networks today, and it only keeps on growing as we witness advances in the AI world.
So, in today’s article, we will be taking a deep dive into what’s a neural network and some of the most popular types of neural networks available today. Moreover, we will be going through explanations for each type along with its applications in the real world.
Neural Networks – And How They Work
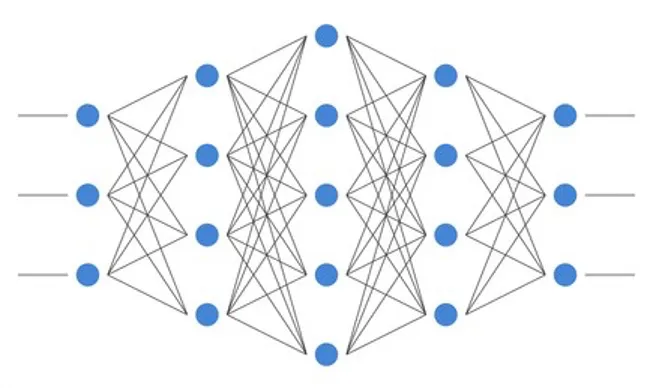
Modeled upon the structure within a human brain, a neural network is a complex structure of interconnected layers, with each layer having a certain number of neurons. Starting from the input layer, each layer passes its outputs to the subsequent layer until it finally reaches the output layer, where the final output is calculated.
To understand how neural networks work, there are certain terms that you need to be familiarized with. Let’s go through them one by one:
Neurons: Neurons are the most critical part of a neural network. In simple terms, a neuron is nothing but a structure that, when provided some input, either fires or not. In simple terms, it either outputs 1 (fires) or 0 (doesn’t fire). For example, if the inputs received are more than 10, the neuron outputs 1; otherwise, 0. Here’s a diagram for illustration.
Weights: These are the numeric values associated with each neuron. The weights are multiplied by the value of the neuron to calculate their output.
Activation function: Once the output of a neuron is calculated, the activation function is applied to it to get the final output that decides if the neuron will fire or not. There are many different activation functions used depending upon the application.
Backpropagation: Backpropagation is the algorithm that makes the neural networks independent and able to be trained by themselves. It lets neural networks calculate the error in their prediction and then use that error to adjust the network’s parameters to better fit the training data, all without requiring any human intervention. Gradient descent is the most basic backpropagation algorithm, but you can also find many other flavors.
That’s pretty much all the basic stuff since the in-depth working of neural networks has many more aspects, but it isn’t within the scope of this article. However, you can dive in here if you’re interested.
What Are Different Types of Neural Networks?
There are many different types of neural networks being used in the industry, depending upon the application and use case. Some of the most popular ones are:
- Feedforward
- MLP
- Recurrent Neural Network
- LSTM
- Convolutional Neural Network
- GAN
Let’s start going through them in a sequential manner:
1. Feedforward Neural Network
Feedforward neural networks were the first type of neural network to appear in the computing world after the backpropagation algorithm was discovered. Unlike other neural networks, feedforward networks, as their name reflects, only work in one direction, i.e., forward. They don’t have any cycles in them to make the data go backward; hence data is only fed in the forward direction, starting from the input layer to the output layer.
While they were heavily used in the 90s, they lost popularity soon afterward since using them for most real-life applications was quite hard. They don’t work well with images or sequential data. Nowadays, you will hardly see anyone using them. But you shouldn’t forget that’s where it all started.
2. Multi-Layer Perceptron (MLP)
MLP stands for multi-layer perceptron. MLP includes neural networks with at least three hidden layers, and they are fully connected to each other, meaning that every neuron from one layer is connected to every neuron in the subsequent layer. Such networks work pretty well with datasets that are not very complex and don’t take a lot of time to train as well. Data travels in both directions in MLPs, both forward and backward.
3. Recurrent Neural Network (RNN)
The highlight of recurrent neural networks that separates them from the networks is that they introduce an idea of retention into the neural networks, where information can be stored. In other words, you can use the information of the previous state to calculate the next state of a neuron.
These cells that can save previous states are called recurrent cells. Except for the input and output layers, all the hidden layers in an RNN use this special type of cells that can store their previous state. This is also referred to as the context. This is why they’re used mainly in applications where the context is vital to calculate something.
For example, the sequence is crucial in understanding textual data. This is why RNNs are mostly used when training on text data, as RNNs can also store the previous word’s information while training on the next one, hence making better sense of sentences.
4. LSTM
LSTM stands for Long-Short Term Memory, and you could think of LSTMs as an upgrade to the RNNs or their tweaked flavor. While RNNs can also be used to store data, they cannot do it for long. And whether you like it or not, after some forward passes, the information will be over-written, mainly due to a phenomenon called vanishing gradients. LSTMs were designed to combat this issue.
LSTMs are designed with a gated structure in neurons, where you can store information for as long as you want. The gates contain input and output functions, and you can control the information coming in or going out of the gates using them.
Here’s a diagram from the Wikipedia to understand their structure better and how gates are used to retrieve the information contained in them:

The gates shown as x in the diagram are what control the input and output in neurons. Each gate has its own weight and sometimes its activation function as well. How do the gates work? Well, the input gate controls how much information to store, while the output gate regulates the flow of information going out of the neuron. Lastly, the forget gate stores the information till it’s not turned on, which removes all the current information from the neuron.
The mathematics here for working of the neuron is a bit complex to be explained here, but feel free to check out more details here.
5. Convolution Neural Network (CNN)
Convolution neural networks are probably the hottest type of neural network for a couple of years now. Given their three-dimensional structure of neurons as compared to the usual two-dimensional in other networks, they offer many advantages, especially for image and speech data, since it’s represented in 3d. CNN has kernels as its basic building blocks that are used to extract features from the training data, which are nothing but a form of vectors that represent arrays of data or pixels.
CNN architecture was specifically built to manage image data better. It works by performing convolutions on the data, which does not just work on the current piece of the pixel but also considers the neighboring pixels, thanks to how convolution works. But even though it was designed for image data and worked excellent on it, it’s being used in the industry for many other applications as well.
Right now, some of its most widely used applications are object detection, edge detection, line detection, face detection, and so on.
6. Generative Adversarial Network (GAN)
Generative Adversarial Networks, more commonly known as GANs, are the latest addition to the world of neural networks from our list. They were designed back in 2014, and ever since, they have been making massive strides, with their different flavors doing wonders in the field of generative modeling.
Unlike the predictive models which we mostly come across, generative models use unsupervised learning to generate new data based on the training data it’s fed. Instead of training on the data and learning it, they learn the underlying distribution, which is used to generate the data so they can generate new instances that belong to the same distribution.
GANs are cleverly designed by using two supervised sub-models such as CNN. One of them acts as the generator model that generates new instances of data, while the other acts as the discriminator that tries to discriminate the output generated by the generator, basically trying to guess whether it’s an actual output or generated by the generator.
GANs essentially act like a 2-players game. A famous example you can use to imagine this is the thief-detective example. In this example, the thief is the generator (tries to fool the detective) while the detective is the discriminator (tries to catch the thief).
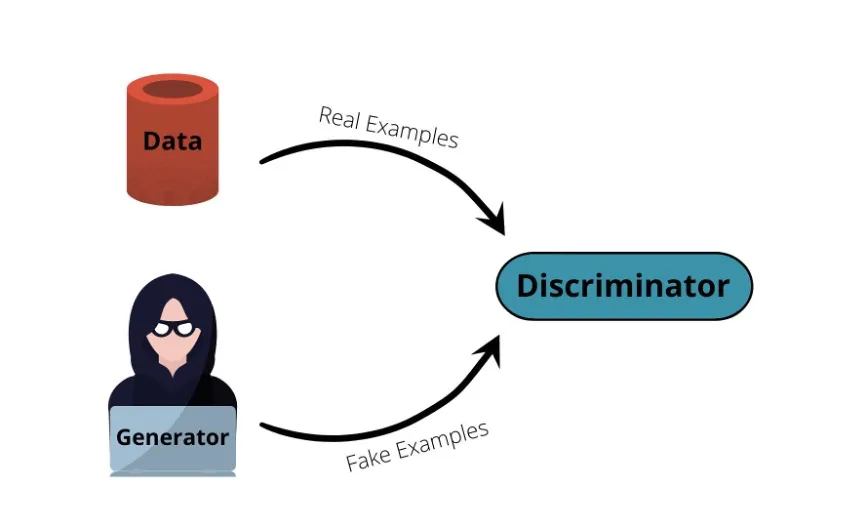
This sequence of generator and discriminator competing with each other continues, and they use the training data to get better and better at their guessing until the generator becomes good enough in generating the images that it’s able to fool the discriminator now. This is how the GANs are trained in a nutshell. You can read more about them here.
Conclusion
Neural networks are an essential part of artificial intelligence and are widely used in most industries today. Unlike machine learning, deep learning is a powerful way that can independently train and perform feature extraction using a backpropagation algorithm and achieve a very high degree of accuracy, even with a relatively small amount of data. However, they’re computationally expensive since the process of backpropagation is quite complex.
Throughout the article, we went through some of the industry’s most widely used types of neural networks today. Not only are they being used in predictive modeling, but they’re also extensively used in generative modeling, where AI is used to generate new images once it learns the underlying distribution for it.
