As a newbie in machine learning, it’s important to understand that building accurate predictive models is crucial for any data science project. One common strategy to increase the accuracy of predictive models is called ensemble learning, where the outputs of multiple models are combined to end up with a more robust and error-free prediction.
Although there are many ensemble learning techniques that data scientists use while building robust machine learning models, one of the most popular ones that we’re going to explore in this article is called stacking.
We’ll go through the complete process of stacking in detail and analyze its benefits along with its limitations. So, let’s dive into the world of stacking in machine learning without any further ado!
Ensemble Techniques – Where Does Stacking Lie?
Traditionally, when combining multiple models, the predictions are simply averaged. However, this approach does not consider each model’s individual strengths and weaknesses. However, stacking, as we’ll see further in the article, is a more sophisticated technique that builds a new model by training it on the predictions of multiple base models.
Stacking has been successful in real-world applications such as image identification and natural language processing. For example, in image identification, stacking could involve using multiple models to predict what objects are present in an image and then combining those predictions to make a more accurate identification.
Some of the most commonly used ensemble techniques in the industry are:
- Bagging
- Boosting
- Stacking
Stacking – What is It & How Does It Work?
Stacking is an ensemble learning strategy that involves combining predictions from several models, known as base models, using the same dataset. When used individually, these base models are considered weak, but when their predictions are combined using a meta-model, they can produce near-accurate results with utmost accuracy. The meta-model can be any machine learning approach, such as linear regression, neural network, or random forest.
The key advantage of stacking is that it can mitigate the individual shortcomings of multiple models while retaining their strengths, resulting in increased performance. For example, stacking can combine the strengths of two models to provide more accurate predictions, with one model being good at detecting local patterns and the other being good at detecting global patterns.
Furthermore, stacking allows for the use of heterogeneous individual learners, which increases flexibility compared to bagging and boosting, where the individual learners are primarily homogeneous.
-

Bagging vs Boosting vs Stacking
-

When Should I Use Ensemble Methods?
-

What is Ensemble Learning? Advantages and Disadvantages of Different Ensemble Models
The Stacking Process Explained
The process of stacking can be broken down into:
- Splitting the Data: The training data is split into two parts, training data (test data), which is the first subset of data, and validation data, which is the second subset.
- Training the Base Models: The next step is to teach the base models on the first subset of the data. Machine learning algorithms can be used as base models, such as decision trees, SVMs, or neural networks.
- Testing the Base models: The base models are then tested on the validation data (second subset) to test their accuracy from which the stack data set can be obtained.
- Training the Meta-Model: The base model’s outputs are used as inputs to the meta-model, combining the predictions and original features as input and generating a final prediction.
Architecture of Stacking
Let’s go through the architecture of stacking to see how it manages to perform so well:
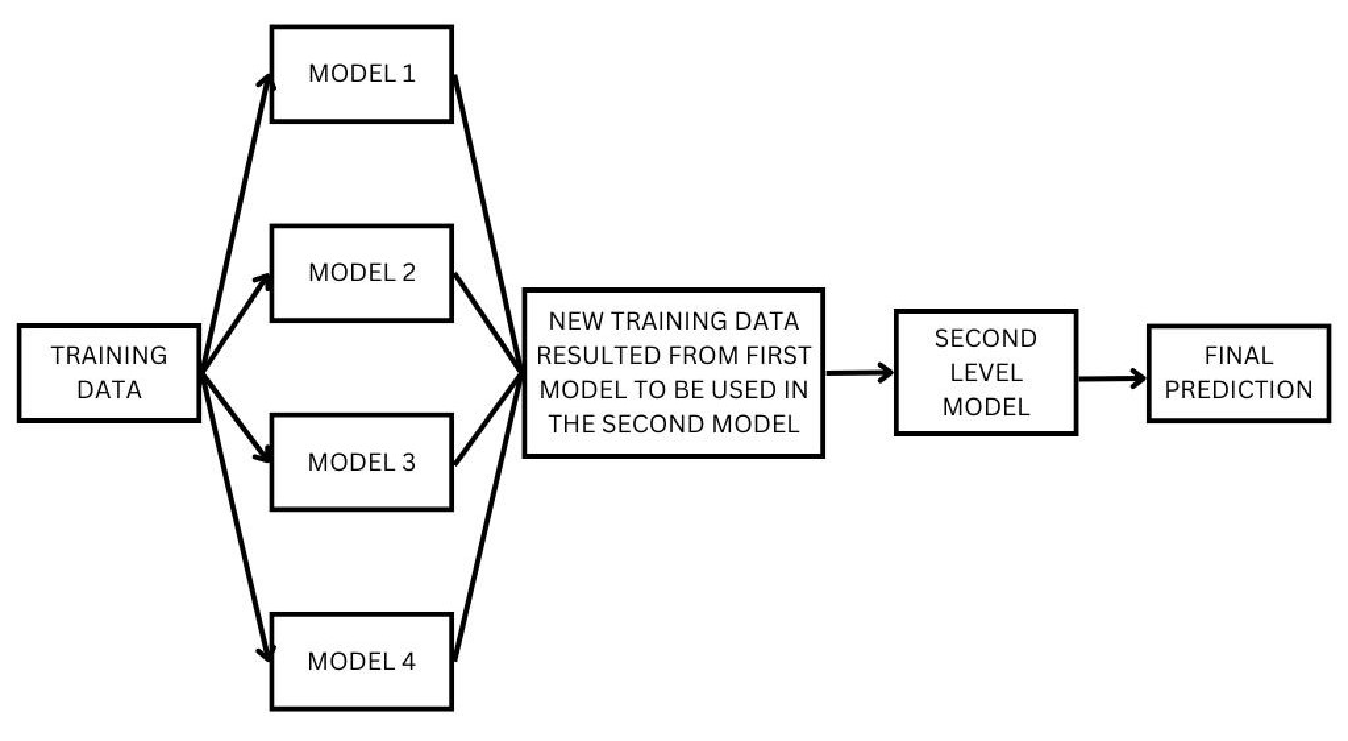
The stacking architecture consists of several key components:
- Training Data: Consisting of n-levels, this is the data used to train the base models, which are trained on different subsets of the training data.
- Base Models: These are individual models that are trained on the different subsets of the training data, resulting in their own predictions.
- Stacked Data Set: The predictions from the base models are combined to create a new dataset, referred to as the stacked data set, which is used to train the meta-model.
- Meta-Model: The stacked data set is used to train the meta-model, which takes in the predictions of the base models as inputs to create the final prediction.
- Final Prediction: The final prediction is obtained from the meta-model, which combines the predictions of the base models to produce an overall prediction with increased accuracy.
For example, consider three algorithms, Random Forest, SVMs, and Gradient Boosting. First, these algorithms are trained individually on the first subset of data (training data). Then they are tested on the validation data. The outputs resulting from the validation data are used to train the meta-model.
Benefits of using Stacking
Here are some benefits of using stacking:
- Enhanced Performance: Stacking can lead to better accuracy and consistency of predictions by leveraging the strengths of multiple models and reducing the impact of their weaknesses.
- Flexibility: Stacking can work with any combination of base models and meta-models, making it adaptable to a wide range of machine learning tasks.
- Reducing Overfitting: Stacking can reduce overfitting, a common problem in machine learning, by combining the predictions of multiple models and reducing their errors.
Limitations of Stacking
While stacking is definitely quite a valuable ensemble learning technique, it certainly comes with its fair share of limitations. Below are some of them that you might want to keep in mind:
- Computing Complexity: Training many models is necessary for stacking, which can be costly and time-consuming. This can be a deal-breaker for applications that require real-time predictions or have limited computational resources.
- Model Complexity: Stacking increases model complexity, making it more challenging to understand and explain, especially in cases where transparency is key, such as medical diagnosis or legal decision-making.
- Data Dependence: Stacking presupposes independence between the base models, which may not always be the case in real-world applications.
Wrap up
Stacking is a powerful machine-learning strategy that strengthens a model by combining the predictions of several weak learners. It uses a dataset to train base models and their predictions as input for a meta-model. Some benefits of stacking include improved performance, adaptability, and the capacity to lessen overfitting. However, it also has drawbacks, such as increased model, computing complexity, and reliance on data independence assumptions.
Nonetheless, stacking has been demonstrated to be a valuable tool in numerous real-world applications, such as picture identification and natural language processing. As a result, it is an essential consideration when developing machine learning models.
