Machine learning automates the creation of analytical models and enables predictive analytics. It’s frequently confused, though not correctly, with artificial intelligence. Machine learning is a branch of artificial intelligence founded on the notion that computers can learn from data, see patterns, and make judgments with little human involvement.
In its most basic form, machine learning relies on preprogrammed algorithms to process input data, interpret it, and forecast output values that fall within a reasonable limit. These algorithms learn from new data, optimize their processes to increase performance, and eventually become more intelligent. This article will familiarize you with the types of machine learning, the Top 12 Machine Learning Algorithms, and a free cheat sheet! So, let’s dive in!
Machine Learning Algorithms
An AI system executes its task using a machine learning algorithm, often predicting output values from the given input data. Machine learning’s driving forces are the algorithms that transform a piece of data into a model. The optimum algorithm relies on the problem you’re trying to solve, the processing power you have at your disposal, and your data type.
Types of Machine Learning
There are four types of machine learning algorithms and are categorized as follows:
1. Supervised Learning
Supervised learning is a subset of machine learning that is defined by its use of labeled datasets to train algorithms that appropriately categorize data or predict outcomes. The labeled data refers to input data that has already been assigned the appropriate output. It entails training the machine or system, where the task-specific training sets and output patterns are given to the system.
Typically, supervising entails keeping an eye on and directing how tasks, projects, and activities are carried out. Applications include risk assessment, image classification, spam filtering, etc.
2. Unsupervised Learning
Unsupervised learning is the second type of machine learning where the users do not have to watch over the model during its training. Since the goal output is not involved, the system receives no training. By determining and adapting to the structural qualities in the input patterns, the system must learn on its own. It employs machine learning techniques to draw judgments on unlabeled data. Unsupervised algorithms operate on unlabeled, unclassified data.
Because we have little to no knowledge about the data, unsupervised learning uses more complex algorithms than supervised learning. This machine learning technique identifies the dataset’s underlying structure, organizes the data into categories based on similarities, and provides the dataset in a compressed format.
Searching for entities like groups and clusters, reducing dimensionality, and performing density estimates are the primary goals of unsupervised learning.
Some of its real-life applications are exploratory data analysis, cross-selling strategies, customer segmentation, image recognition, etc.
3. Semi-supervised Learning
Semi-supervised learning is needed when working with data where labeling instances is difficult or expensive. When building models, semi-supervised learning employs a combination of a sizable amount of unlabeled data and a modest amount of labeled data.
Combining supervised machine learning, which utilizes labeled training data, with unsupervised learning, which uses unlabeled training data, makes up this approach to machine learning.
Neither supervised learning algorithms, nor unsupervised learning algorithms can effectively handle combinations of labeled and untellable data. Specialized semi-supervised learning methods are therefore necessary.
Applications include text document classifiers, predicting house prices, speech analysis, etc.
4. Reinforcement Learning
In reinforcement learning, another type of machine learning, an intelligent agent (computer program) interacts with the environment and picks up how to behave. This deep learning method includes a component that enables you to maximize the percentage of the cumulative reward. This learning method, utilizing various techniques, teaches you how to achieve a challenging goal or maximize specific dimensions.
By executing and observing the outcomes of those actions, an agent learns how to behave in a given environment via reinforcement learning, a feedback-based machine learning technique. The agent receives feedback for each positive activity and is penalized or given negative feedback for each adverse action. The agent engages with the environment and independently explores it.
In reinforcement learning, an agent’s main objective is to maximize positive reinforcement while doing better. The agent learns through trial and error, and depending on its experience, it develops the skills necessary to carry out the mission more effectively.
Some real-life applications of reinforcement learning are text summarization, trajectory optimization, robotic manipulation, etc.
-

Can Data Analysis Be Automated? (We Find Out)
-

12 Data Analysis Techniques You Need to Know
-

Will Algorithms Erode our Decision-Making Skills?
Top 12 Machine Learning Algorithms
Dozens of machine learning algorithms are being used in the industry today. Since we obviously cannot go through them all here, let’s look at the top 12 machine learning algorithms that are the hottest in the industry.
1. Naïve Bayes Algorithm
When discussing classification issues, “Naive Bayes” refers to a probabilistic machine learning technique based on the Bayesian probability model. The algorithm’s essential premise is that the qualities being considered are unrelated to one another and that changing the value of one does not affect changing the value of the other.
Despite its simplicity, the classifier performs admirably and is frequently used because it outperforms more complex classification techniques.
The development and application of a naive Bayesian algorithm are simple. It works well for producing predictions in real-time and can handle large datasets. This algorithm falls under the category of supervised learning.
Example:
Its applications include sentiment analysis and prediction, spam filtering, document classification, etc.
2. Linear Regression Algorithm
Linear Regression is a supervised machine learning algorithm. Based on the provided independent variable, linear regression performs the task of predicting a dependent variable. As a result, this regression technique determines if a dependent variable and the other independent variables are linearly related. Hence, this procedure is called linear regression.
The most fundamental kind of regression is linear regression. We can comprehend the relationships between two continuous variables using simple linear regression.
The following graph shows the output (dependent variable) on the Y-axis and the independent variable on the X-axis. The best fit line for a model is the regression line. Finding this best fit line is the primary goal of this algorithm.
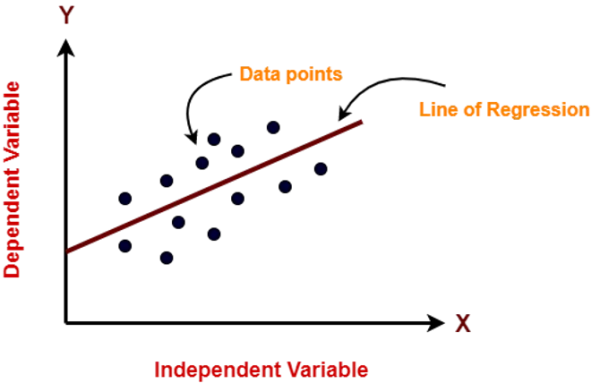
Example:
A linear regression algorithm might be used when the police department runs a campaign to reduce street crime; the doctors observe how a drug affects a patient, etc.
3. Logistic Regression Algorithm
One of the most often used Machine Learning algorithms within the category of Supervised Learning is Logistic Regression. Using a predetermined set of independent factors, this algorithm is used to predict the categorical dependent variable.
The main goal of logistic regression is to calculate the likelihood of an event happening, given the available historical data. As a result, the result must be a discrete or categorical value. It can be either Yes or No, 0 or 1, true or false, etc. Rather than providing the exact values of 0 and 1, it gives the probabilistic values that fall between 0 and 1. The outcome that was predicted is constrained to a small set of variables.
Example:
An example of logistic regression could be applying machine learning to determine if a person is likely to be infected with a virus or not.
4. Linear Discriminant Analysis Algorithm
This technique locates linear combinations of features that divide the various input data. An LDA algorithm’s objective is to analyze a reliable variable as a linear union of elements. It is an excellent method of classification. This algorithm performs calculations for each class while looking at the statistical properties of the supplied data. The class value and, subsequently, the variance across all classes are measured.
It evaluates the input data based on independent variables while modeling the distinctions between classes. Information about the class with the highest value is included in the output data. The techniques for linear discriminant analysis perform best when differentiating between well-known categories. We employ an LDA method when it is necessary to categorize multiple factors mathematically.
Example:
Some examples of the LDA algorithm would be classifying emails as spam or important, dimensionality reduction, etc.
5. Decision Trees Algorithm
A non-parametric supervised learning algorithm is a decision tree. It is organized hierarchically and has a root node, branches, internal nodes, and leaf nodes. Each branch of the tree displays the results of the tests at each node.
A decision tree begins with a root node with no incoming branches, as shown in the diagram below. The internal nodes, called decision nodes, are fed by the root node’s outgoing branches. Both node types undertake assessments based on the available attributes to create homogenous subsets represented by leaf nodes or terminal nodes. All of the outcomes within the dataset are represented by the leaf nodes.
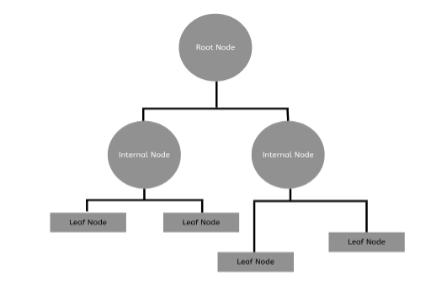
EXAMPLE:
An application of this algorithm would be when we have to make a particular decision with multiple possible outcomes, for example deciding which pet animal to keep or where to go for vacations.
6. K-Nearest Neighbors Algorithm
The K-Nearest-Neighbor algorithm categorizes new use cases (or data points) by dividing them into distinct classes and storing all known use cases. Based on how closely the most recent use cases match the already available ones, this classification is completed. It is a supervised machine learning technique that considers a certain number of surrounding points when categorizing and dividing the known n groups. The algorithm learns with each step and iteration; therefore, no particular learning phase is required. It calculates the likelihood that a data point belongs to a specific category or not. To decide which group a certain data point belongs to, it examines the data points around that point.
Example:
Real-life applications of KNN algorithms include facial recognition, text mining, recommendation system, etc.
7. Anomaly Detection Algorithm
In Anomaly Detection, a method is used to spot abnormal patterns that resemble the standard pattern. Outliers are these unusual trends or data points. They are an occasional occurrence. This insight stands out considerably from the others. This can be the result of measurement variability or an error. Many enterprises that require intrusion detection, fraud detection, etc., have discovered these outliers a top priority.
Example:
Anomaly detection algorithms are used in data cleaning, event detection in sensor networks, ecosystem disturbances, etc.
8. Support Vector Machine Algorithm
Support vector machine algorithms analyze the data used in classification and regression analysis. They fall under the category of supervised machine learning algorithms. By giving training examples, each set is flagged as falling into either of the two categories; they essentially categorize the data. The algorithm then creates a model that gives new values to either or both categories.
Example:
Examples of an SVM algorithm are speech recognition, texture classification, facial expression classification, etc.
9. Random Forests Algorithm
Random forests, sometimes known as “random decision forests,” is a type of ensemble learning that combines different algorithms to produce better classification, regression, and other task-related results. Although each classifier works best when combined, they are all weak individually. Input is entered at the top of the algorithm’s “decision tree” at the start. The data is then split into smaller and smaller sets based on specific variables as it moves down the tree. Random forest algorithms use multiple decision trees to address classification and regression issues.
It is a supervised machine learning approach in which various decision trees are constructed on multiple training data. When a significant portion of the dataset is missing, these techniques can help estimate the missing data and often maintain accuracy.
Example:
This algorithm finds applications in recommendation engines, gene classification, biomarker discovery, etc.
10. XGBoost Algorithm
The XGBoost, Extreme Gradient Boosting algorithm is about ten times faster than current gradient booster techniques. It has an extremely high predictive power, making it the most excellent option for event accuracy. It also features a linear model and a tree learning algorithm. Numerous objective operations, including regression, classification, and ranking, are included in this algorithm.
One of its most intriguing features is that the XG Boost is also referred to as a regularized boosting approach. It provides extensive support for various languages, including Scala, Java, R, Python, Julia, and C++, and helps reduce overfit modeling.
This algorithm can be used for sales forecasting.
11. K-Means Clustering
Clustering tasks are carried out via the distance-based unsupervised machine learning algorithm K-Means. With the help of this approach, you may group datasets into clusters (K clusters), where the data points from one cluster remain uniform, and the data points from two distinct clusters remain diverse.
Example:
K-Means clustering is helpful in applications such as clustering Facebook users with common likes and dislikes, document clustering, etc.
12. Artificial Neural Networks
Artificial neural networks are machine learning algorithms that solve challenging issues by modeling the neural function and connections of the human brain.
The computational model of an ANN contains three or more interconnected layers that process the incoming data. The input layer, or the top layer, consists of the neurons that transmit data to lower layers. The concealed layer is the second layer, also known as the neuronal layer. The elements of this layer use several data transformations to modify or refine the information obtained from various earlier layers. The output layer, the third layer, transmits the final output data for the issue.
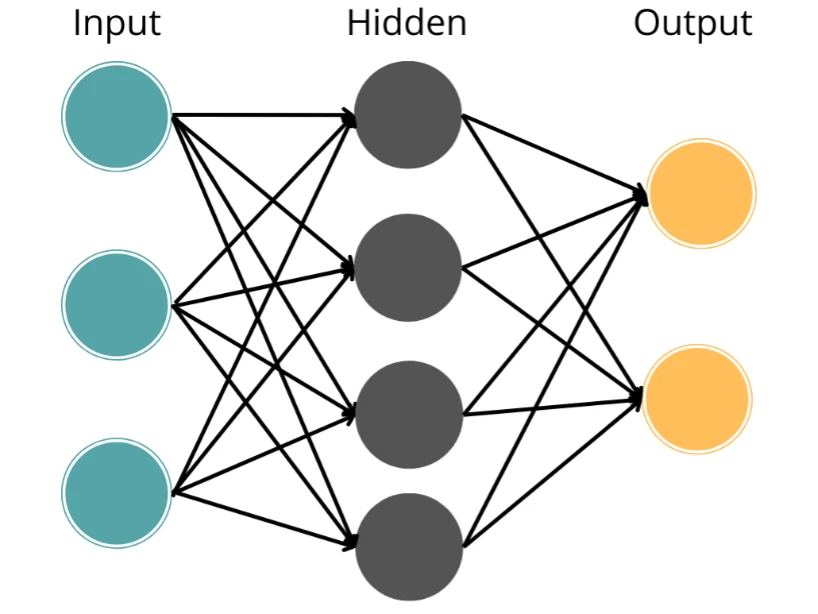
Example:
ANN algorithms find applications in door locks, thermostats, smart speakers, detection systems, autonomous vehicles, etc.
Machine Learning Algorithms Cheat Sheet
That’s it for today, guys! We have gone extensively through some of the industry’s most used machine learning algorithms. However, all the information might have been too much for you to digest at once. So, take it easy, and give this article multiple reads if required, and hopefully, everything will be clear before long.
Lastly, here is a little cheat sheet I’ve prepared for you to easily remember all the algorithms, along with their types and a summary of what they do. Cheers!
| ML Algorithm | Type | Function |
|---|---|---|
| Naïve Bayes Algorithm | Supervised Learning | Mainly used for classification and predicting the probability of different classes based on various attributes. |
| Linear Regression Algorithm | Supervised Learning | Predicts the output based on the input. |
| Logistic Regression Algorithm | Supervised Learning | Predicts the probability of a target variable. |
| LDA Algorithm | Unsupervised Learning | Reduces the number of features to a manageable number before classifying. |
| Decision Trees Algorithm | Supervised Learning | Creates a training model to predict the value of the target variable |
| KNN Algorithm | Supervised Learning | Classifies new data points into their relevant, already stored categories. |
| Anomaly Detection Algorithms | Supervised, Unsupervised, Semi-supervised | Detects the data points that do not fit a dataset’s normal behavior. |
| SVM Algorithm | Supervised Learning | Categorizes the input data into classification or regression and then analyzes it. |
| Random Forests Algorithm | Supervised Learning | Builds multiple decision trees and merges them for a more accurate and stable prediction. |
| XG Boost Algorithm | Supervised Learning | Energizes and boosts the computational speed and performance of the model. |
| K-Means Algorithm | Unsupervised Learning | Groups datasets into clusters. |
| Artificial Neural Networks | Supervised, Unsupervised, Reinforcement Learning | Delivers output based on predefined activation functions. |
