Recent advancements in the field of AI have left us with a large number of algorithms. Although the newer algorithms get better and better at handling the massive amount of data available, it gets a bit tricky to keep up with the more recent versions and know when to use them.
However, luckily, most of the time, these new algorithms are nothing but a tweak to the existing algorithms, improving them in some aspects. So, if you have a solid concept of the older algorithms, learning and applying the newer ones becomes a breeze.
With that said, two such topics are decision trees and random forests. Although their relationship is quite literally explained in their names, today, we will see what exactly is the difference between both algorithms and what aspect of decision trees the random forests improve. Moreover, we will also be seeing how one can choose which algorithm to use.
Here’s a summarized side-by-side comparison table between decision trees and random forests, so you can pick whichever you want based on your specific needs.
| Decision Tree | Random Forest |
| It is a tree-like structure for making decisions. | Multiple decision trees are combined together to calculate the output. |
| Possibility of Overfitting. | Prevents Overfitting. |
| Gives less accurate results. | Gives accurate results. |
| Simple and easy to interpret. | Hard to interpret. |
| Less Computation | More Computation |
| Simple to visualize. | Complex Visualization. |
| Fast to process. | Slow to process. |
I do think it’s wise to further dig into what a decision tree is, how it works and why people use it, and the same for random forests, and a bit more on the specifics on how they differ from each other. So, let’s get going!
What is a Decision Tree?
Understanding decision trees and how they work is critical to understanding the difference between them and random forests. Once you have a sound grasp of how they work, you’ll have a very easy time understanding random forests.
Decision trees are supervised learning algorithms mainly used for classification problems. However, they can also be used for regression problems. Decision trees are quite literally built like actual trees; well, inverted trees. Unlike real-life trees that spread upwards, decision trees start from the top and spread downwards, with branches splitting till they reach the leaf nodes.
Let’s go through some basic terms that you’ll need to understand decision trees properly:
- Node: Each data point in the decision tree is referred to as a node, irrespective of its position in the structure. So, all three features, namely Humidity, Weather, and Windy, represent a node.
- Root: The root is where the tree starts from. It’s the node at the top-most position in the decision tree, and every tree has only a single root node. In the above diagram, the humidity represents the node.
- Split: The splitting point is crucial in a decision tree. It determines how well the tree can classify the data. It’s where a node is further split into multiple nodes. Splitting is usually done by calculating either information gain or entropy. The lines after each node are the splitting points in the above diagram.
- Leaf: The leaf node is the endpoint, where no further splitting can happen. A tree can have multiple leaf nodes. The above diagram has multiple leaf nodes labeled ‘Yes’ or ‘No’.
That’s pretty much all the terminology you’d need to be familiar with; let’s jump on to how they work now.
How Do They Work?
In this section, we’ll dig into what the decision trees look like when in action. For the sake of simplicity, let’s take the classic golf-playing example of predicting whether or not to play golf based on the weather conditions (weather, humidity, windy).
Basically, we have three weather attributes, namely windy, humidity, and weather itself. And based on these, we will predict if it’s feasible to play golf or not. The target variable here is Play, which is binary.
Here’s the training data:
| Weather | Humidity | Windy | Play |
| Sunny | High | False | Yes |
| Sunny | Low | False | Yes |
| Overcast | High | True | No |
| Sunny | Low | True | Yes |
| Overcast | Low | False | Yes |
| Sunny | High | True | No |
| rainy | high | false | No |
The aim is to train a decision tree using this data to predict the play attribute using any combination of the target features. Once trained, the features will be arranged as nodes, and the leaf nodes will tell us the final output of any given prediction.
Once the decision tree is fully trained using the dataset mentioned previously, it will be able to predict whether or not to play golf, given the weather attributes, with a certain accuracy, of course. If you’re interested in how to train a decision tree classifier, feel free to jump in here.
Currently, the training of the model is outside the scope of this article, but here’s how the decision tree will look after its trained.
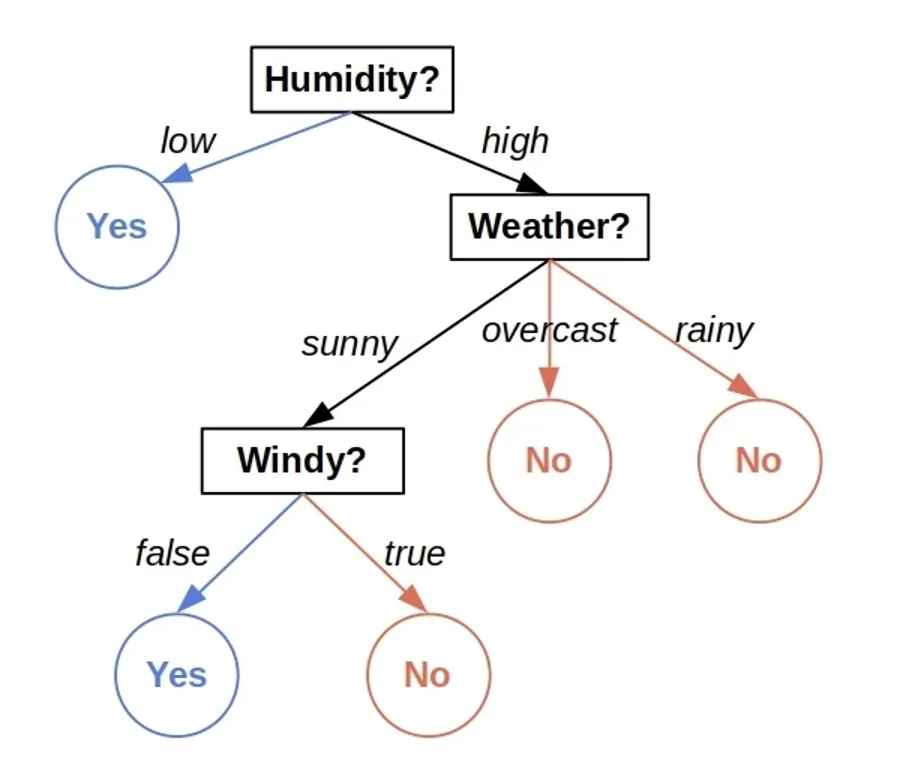
An important thing I’d like to mention here is that while training the decision tree and arranging the nodes, there’s one crucial question that I want you to ponder: how do we arrange the features, and how do we split them? In more technical terms, what should be the root node, and how long should we keep splitting the nodes?
The answer? Information Gain. Let’s explain the term briefly in the following section, but feel free to check out more details about its working here.
Information Gain
During the training process, when you have multiple split options at hand, you calculate the current entropy and the entropy for each option. Entropy basically tells you the extent of randomness in some particular data or node in this case. The information gain at any given point is calculated by measuring the difference between current entropy and the entropy of each node.
Based on these numbers, you calculate the information gain you’d get by going down each path. This essentially tells you how well you can separate the data by picking certain splits. The greater the information gain, the better you can split the data using the tree nodes. Hence, you choose the path of the biggest information gain.
That’s enough to understand the decision trees and how they work. Now, let’s move on to the random forests and see how they differ.
Random Forests – What’s the Difference?
The good news is that once you conceptualize how decision trees work, you’re almost entirely set to understand random forests as well. They’re wholly built upon decision trees and just add the concept of ‘boosting’ on top of them.
So essentially, a random forest is just a collection of a huge number of decision trees trained together. Instead of taking the output from a single decision tree, they use the principle of ‘majority is authority‘ to calculate the final output.
Here’s a diagram depicting the flow I just described:
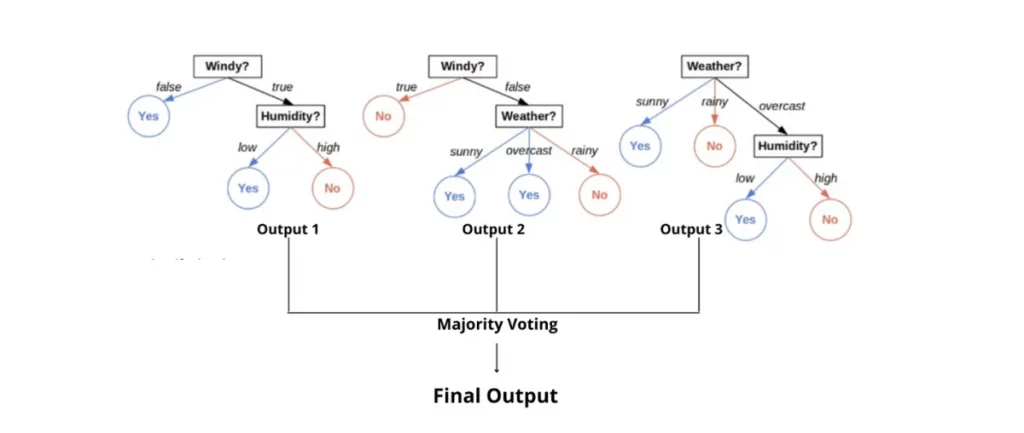
The logic on which decision trees are built is pretty straightforward. In fact, it’s what we all are mostly using in our everyday lives subconsciously. Well, don’t get me wrong; the simplicity of decision trees doesn’t mean they don’t work. They produce pretty good results when it comes to most of the machine learning problems, and they’ve been used in the industry for quite some time now.
However, there are some problems that decision trees face, such as overfitting or biasness. This essentially means that even though your decision tree will seem to perform great when it comes to the training data, it wouldn’t deliver as great results when it comes to the real-world data that actually matters. In a nutshell, decision trees lose their ‘generalizability.’
Now, this is where random forests come into play. They handle noise, bias, and variance in an excellent manner, and most of the credit goes to the concept of ‘boosting’ that they’re built upon. The inherent over-learning and biasness of decision trees are solved using a concept similar to ‘averaging’, making the random forests quite generalizable and hence suitable for practical data, not just training.
However, you need to understand the concept of boosting to know how random forests achieve this. So, let’s briefly define it.
What is Boosting?
Boosting is a widespread term used in machine learning. In essence, it simply means an ensemble of any kind of model. Instead of using the output from a single model, this technique combines various similar models with a slight tweak in their properties and then combines the output of all these models to get the final output.
This purpose is to reduce bias and variance compared to using the output from a single model only. And unsurprisingly, it works like a charm. If you think about it, it’s pretty intuitive. What would you prefer? Asking a single person for a particular opinion or asking a bunch of people and looking at what most people said? Obviously, the second choice is better since we’re now less prone to any bias a single person could have.
The same concept enabled people to adapt random forests in order to solve the problems they faced with decision trees. With minor tweaking, but essentially using the same principle or algorithm, random forests greatly improve the performance.
Decision Trees Vs. Random Forests – What Should You Use?
The major difference between the two algorithms must be pretty clear to you by now. However, when it comes to picking one of them, it gets somewhat confusing at times. Undoubtedly, going with either decision trees or random forests is quite safe, and both provide quite workable results in most cases. However, to make the final call, the most important things to consider are processing time and dataset complexity:
Processing Time/Cost
Since random forests function as a bunch of decision trees working together, it’s pretty obvious that they will take more processing time while making predictions and even a longer training time. Also, in practice, there are not just a bunch of decision trees put together; rather, there might even be hundreds of them. So, the processing cost and time increase significantly. And unless you don’t have high processing or training capabilities, you might want to think twice before using random forests over decision trees.
Dataset
One of the major reasons why random forests outperform decision trees is their ability to generalize the model. However, it’s essential to know that overfitting is not just a property of decision trees but something related to the complexity of the dataset directly. Some datasets are more prone to overfitting than others. If you’re using a dataset that isn’t highly complex, it’s possible that decision trees might just do the trick for you, maybe combined with a bit of pruning.
So, don’t be too fast to jump to random forests since they also have their downsides. Instead, study your dataset in detail first, and only if there’s a significant improvement in switching to them consider switching to them. At the end of the day, your aim should always be to make reasonable predictions by considering the tradeoffs, not just using the most complex algorithm available.
-

Batch Size and Epoch – What’s the Difference?
-

How AI can be used in Decision making
-

The 4 Types of Analytics Explained (With Examples)
Key Takeaway
Decision trees and random forests are both built on the same underlying algorithm. A tree-like structure with several nodes and split points is created, which is then used to make predictions. The major addition that random forests bring to this system is roughly the idea of ‘averaging’ and using multiple decision trees side by side instead of trusting only a single one. As a result, the outputs of all the decision trees are combined to calculate the final output.
Throughout the article, we saw in detail how the algorithms work and the major differences between the two. It’s important to note that neither of them is totally better than the other, and there are scenarios where you could prefer one over the other and vice versa.
That’s it for today; I hope you enjoyed reading the article!