In the quest to understand and predict customer behavior, companies often rely on vast databases filled with valuable information, ranging from customers’ browsing patterns to their engagement on the company’s website. However, constructing an effective model to decipher this intricate data can be challenging. Traditional approaches, like using a single decision tree, often fall short in accuracy and struggle to generalize new data due to overfitting, ultimately hampering the desired predictions.
This is exactly where bagging algorithms come in! By harnessing the power bagging algorithms such as Random Forests, companies can unlock a more reliable and robust approach to modeling, enabling them to make accurate predictions, prevent overfitting, and gain valuable insights into feature importance.
In this article, we’ll explore the advantages of using bagging algorithms, such as Random Forest, over single decision trees, shedding light on their transformative potential for businesses seeking actionable intelligence from complex datasets.
Decision Trees & Bagging Algorithms – How are they related?
Bagging, short for bootstrap aggregating, involves creating multiple models and combining their predictions to make more reliable decisions.
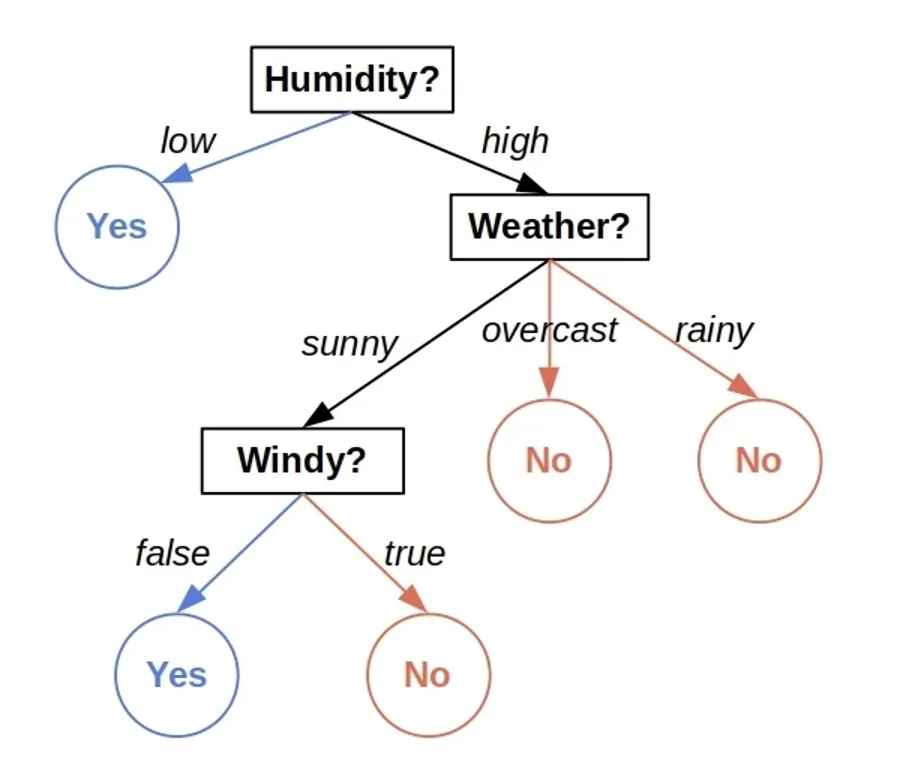
For example, imagine you’re trying to predict whether a student will pass or fail an important exam. You gather data on their study time, previous grades, and extracurricular activities. One approach to making this prediction could be by using a decision tree, which is like a flowchart that asks questions and leads to a final prediction. However, decision trees have limitations. They can be overly simplistic, prone to making errors, and struggle to handle complex relationships within the data.
So, instead of relying on just one decision tree to make the prediction, think of bagging algorithms like a team of experts (decision trees) working together, and then voting to make the final prediction – sounds better, no?
One of these powerful algorithms is Random Forest – It creates a group of decision trees, each trained on a different chunk of the data. These trees collaborate and combine their predictions, just like a team brainstorming ideas. By doing so, Random Forest provides a more accurate and reliable prediction than a single decision tree ever could.
This approach brings stability, reduces the impact of unusual cases, and helps make better-informed decisions in areas like finance and healthcare. It’s like having a group of wise advisors guiding you toward smarter choices.
If you are in a rush, find here a take-home comparison table for you that summarizes the pros and cons of both a random forest and a decision tree, along with situations that will help you determine when to use which model:
| Random Forest | Single Decision Tree | |
| Accuracy | Higher accuracy | Lower accuracy due to less feature space |
| Interpretability | Difficult to visualize and expensive to train | Easy to interpret and requires fewer computational resources |
| Overfitting | Fewer chances of overfitting by taking the average of multiple trees | Prone to overfitting when the tree is deep/complicated |
| Robustness | Can handle outliers | Sensitive to noise and outliers |
| Feature Importance | Provides a measure of feature importance | No feature importance |
| Parallelization | It can be parallelized easily | It cannot be parallelized |
| When to Use | Large datasets with high dimensionality and highly accurate results are needed | When an interpretable model is required |
Advantages of Using Bagging Algorithms
Let’s look at how advantageous working with bagging algorithms can be in relation to using a single decision tree:
- Since a single decision tree can become prone to overfitting when it becomes too complicated, combining multiple decision trees in a random forest reduces the variance in the results, which leads to better generalization.
- These algorithms are much less sensitive to missing data, noise, and outliers, which makes their results more reliable and accurate. Therefore, making the model more robust.
- Results are produced more quickly when the model is parallelized while training large datasets.
- Bagging algorithms such as random forest provide a measure of feature importance. This is the act of identifying which features have the most impact on the output of the model. This is very useful when it comes to making certain important decisions.
Decision Trees: Advantages and Limitations
Decision trees are tree-based machine learning models which split the data into small subsets according to the critical features until they reach a conclusion. Let’s explore why they are considered to be ideal in some cases but not all:
Advantages:
- The set of rules for making decision trees is easy to understand and visualize, which makes them very easy to interpret.
- They do not require parameters because they don’t make any assumptions about the relationship between the data, the target variables, or features.
- They can easily handle missing values without data imputations.
- They can make local decisions based on the individual features even if the dataset is noisy or in the presence of outliers.
- They can handle datasets with multiple features, which makes them efficient.
Limitations:
- If a dataset becomes too large or complicated, your decision tree also becomes prone to overfitting, which in turn leads to poor generalization performance.
- Decision trees are considered to be unstable because they are susceptible to minor changes in the data, i.e., even small changes in they may result in significant changes in the structure of the tree.
- A reason behind inaccurate predictions in decision trees is that they can become biased toward specific values or features, which results in unequal prediction accuracy along different parts.
- If you are working with continuous variables, then there may be better options than decision trees because they only perform well with discrete splits.
- They cannot capture the complex relationship between the target variables and the various features which limit their expressiveness.
Example – Bagging (Random Forests) in Action
Let’s look at an example of a medical situation where the results from a random forest algorithm bested those of a single decision tree.
While predicting the likelihood of heart disease, researchers made a dataset of over 300 samples that contained parameters such as age, sugar levels, blood pressure, etc. Then, two independent models were trained – random forests and a single decision tree.
As a result, random forests outperformed the single decision tree trained by almost 11% with an accuracy of 88.7%. Hence, it was concluded that bagging algorithms are best suited for larger datasets with multiple parameters because of their ability to handle the complex relations between the different parameters without overfitting the dataset.
-
Overfitting and Underfitting – Common Causes & Solutions
-

Bagging vs Boosting vs Stacking
-
Decision Trees Vs. Random Forests – What’s The Difference?
Wrap Up
By now, you must have a clear understanding of the advantages a bagging algorithm such as random forest has over a single decision tree because when you combine multiple decision trees with random forest, it increases the accuracy of your results and makes your model immune to overfitting while also providing feature importance measures.
However, one must be careful while selecting a model for their task because a random forest may not be the ideal choice for every scenario, as a single decision tree may prove to be a better option when working with smaller datasets or where the main concern is interpretability. Therefore, to make robust models, you must learn the advantages and limitations of every model first.