Imagine you’re a data scientist and you’re in a situation where you need to collect insights from various sources, such as financial statements and market trends, etc., to make predictions about the company’s stock prices. Now, the model you’ve developed to make the needed predictions keeps giving you inaccurate information every time you feed it with new datasets and has a high variance.
Well, what can you do in such a situation? You know this is happening since the model you trained has high variance, resulting in overfitting, but you’re not sure how to avoid it. Well, luckily this is exactly where bagging steps in. Curious how bagging reduces variance? Then you have come to the right place. Let’s get going!
What Is Bagging?
Bagging, also known as Bootstrap Aggregating, is a type of ensemble learning method that is widely used in various machine learning processing, mostly by a combination with other algorithms. Bagging works by using the bootstrapping approach to create multiple base models and combines their predictions to make a strong learner with reduced variance and higher predictive performance.
How Bagging Works
The bootstrapping process selects samples (with replacement) from the given training dataset to create diverse training sets for the base models. Each model is considered different because samples are taken randomly; therefore, each base model focuses on a different aspect of the data.
Once you have all your base models, they are used to make predictions. By either averaging or by majority voting, the previously made predictions are all combined to make the final model. This process reduces the variance, cancels out the chances of errors made by an individual model, and detects any underlying patterns in the dataset.
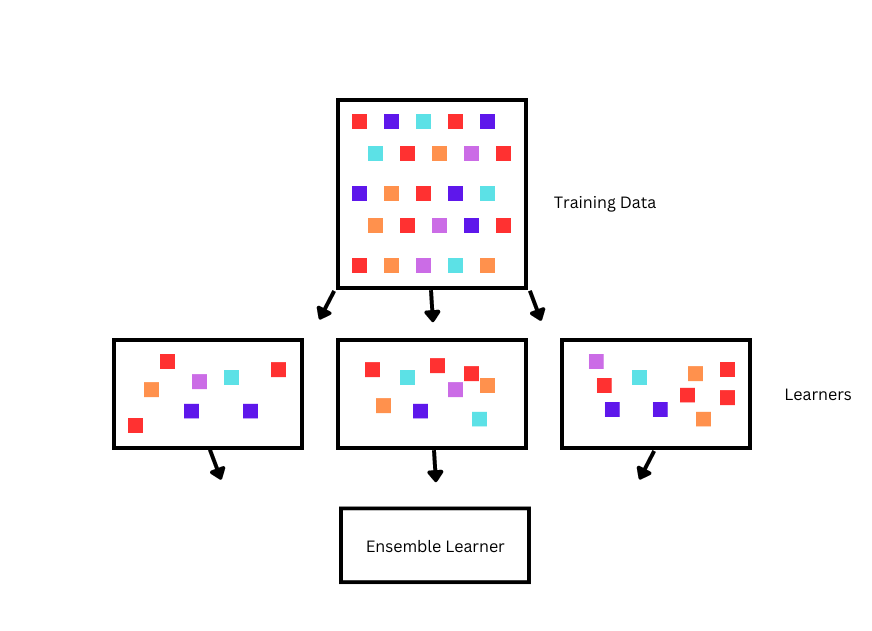
To make the base models for the algorithms, you can combine various models such as regression models, decision trees, and neural networks.
How Does Bagging Reduce Variance?
Bagging reduces variance by creating multiple diverse base models using bootstrapping, which involves selecting random samples with replacement from the original dataset. Each base model is trained on a different subset of the data, capturing different patterns and relationships. However, that’s just scratching the surface. Let’s explore this in further detail below:
- Creating Multiple Diverse Base Models
Bagging begins by creating multiple diverse base models using bootstrapping. Bootstrapping is a process that selects random samples with replacement from the original dataset to create new, smaller training datasets. By training each base model on a different subset of the data, we ensure that they capture different patterns and relationships in the data. This diversity in base models helps to create a more robust ensemble.
- Averaging Out Errors
When each base model makes predictions, the errors they make are usually uncorrelated. That is, one model’s errors will not systematically align with another model’s errors. When we average the predictions of these models, we reduce the overall error of the ensemble. Why? Well, it’s because the errors of one model are likely to be offset by the correct predictions of another model.
For example, suppose you’ve trained three different ML models to predict housing prices, i.e., A, B, and C. But the problem is that while A overestimates the price of small houses, B overestimates the price of large houses, C underestimates the price of houses near schools. So now the problem is that if you need to pick a single model out of these three, it’ll become very hard to do so since none of them is suitable. However, if you use bagging and average out the predictions of these three models, the overestimations and underestimations will cancel each other out and you’ll get a much more accurate prediction.
- Reducing Overfitting
One of the main reasons for high variance in a model is overfitting, which occurs when a model performs well on the training data but poorly on new, unseen data. Overfitting happens because the model has learned the noise in the training data rather than the underlying pattern. Bagging reduces overfitting by training multiple base models on different subsets of the data, ensuring that each model focuses on a different aspect of the data. When these diverse models are combined, the ensemble is less likely to overfit, as the noise present in individual models is canceled out.
- Wisdom of the Crowd Effect
The “wisdom of the crowd effect” refers to the idea that the collective prediction of a group of learners is mostly ends up being more reliable than the predictions made by an individual learner. Bagging leverages this effect by combining the predictions of multiple base models. Even if some of the base models make errors, the combined prediction is likely to be more accurate, as the errors of individual models are averaged out.
Some Practical Examples of Bagging
Let’s some practical examples of bagging that are currently being used in different fields:
Finance
In finance, bagging is used to predict stock prices of companies. When traditional methods fail to capture the complexity in your dataset, models such as decision trees or neural networks are used which are trained on bootstrapped samples of the historical data of the company’s stock prices.
Research suggests that bagging successfully captures the non-linear relationship between variables, reduces variance by averaging errors of individual models, and accurately predicts stock prices.
Remote Sensing
According to research, when comparing bagging algorithms with an algorithm based entirely on support vector machines (SVMs), it was found that bagging reduced variance and improved land cover classification compared to a great deal.
Natural Language Processing
NLP is another field where bagging is used heavily to develop machine learning models. There are a lot of NLP use-cases such as classifying online reviews where bagging produces exceptional results while optimizing variance, especially when compared to the traditional ML techniques.
Wrap up
Bagging is a potent machine learning tool that not only improves the predictive performance of a model but also makes it more robust, primarily when you work with a dataset that is very complicated or prone to overfitting. This is achieved by creating diverse learners through bootstrapping to reduce the variance.
Moreover, bagging is also used when it is critical to use stable and accurate predictions. However, just like all other ML techniques, its highly recommended that you first understand the limitations and strengths of bagging before deciding to use it.
