Deep learning can be a daunting subject at times. As a beginner, you often get exposed to various concepts that seem similar. Don’t worry; you’re not alone. And it gets a lot better once you’ve built a solid understanding and intuition of the concepts.
Among such concepts, batch size and epoch are the most frequently occurring ones disturbing the freshers. While they’re relatively different and serve different purposes, they seem pretty similar initially. So today, we will be looking at the difference between batch size and epoch, along with how they’re important in deep learning and neural networks.
So, let’s start without any further ado.
Gradient Descent – The Backbone
Since batch size and epoch are both hyperparameters that affect how a deep neural network is trained, it’s essential to understand how a neural network works first. Gradient descent is the major backbone of the neural networks that enables them to train and update their weights – optimization. Let’s see what it is.
Gradient simply means how a certain slope declines, and descent, well, refers to descending down to something.
In the context of deep learning, gradient descent refers to an iterative algorithm that is used to find the best parameters by iteratively moving towards the minima of a curve.
The term iterative here essentially means that we go through the algorithm multiple times, and with each pass of the algorithm, we get a little closer to the minima. This continues until we finally reach the minima – where the error is the least.
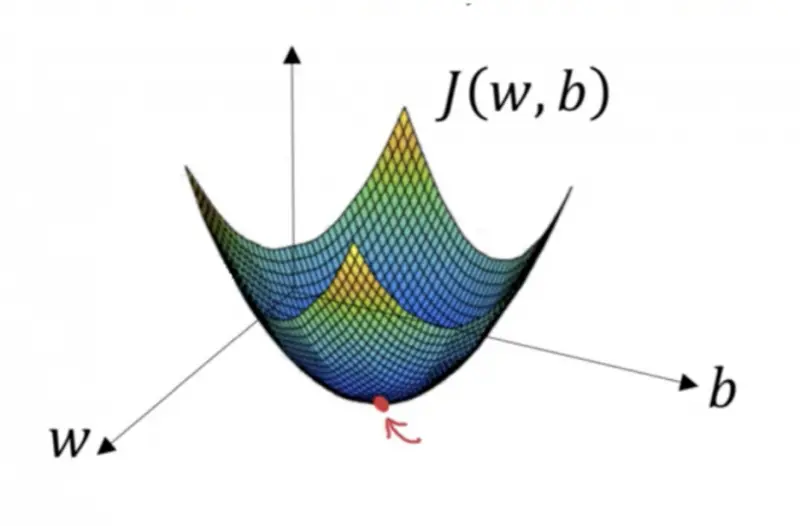
You might be wondering why we use a gradient here. Well, the gradient tells us the direction of the slope, subsequently enabling us to move in that direction. Consider the figure below. The aim is to reach the point marked red. No matter what starting position we have, we will eventually reach our aim – the minima; if we calculate the gradient at each point and then move towards it (descent). However, how fast we move is controlled using the learning rate – specified at the start of the algorithm.
How Does It Work? A Practical Illustration
Let’s understand the complete process using a real-life example without getting into the boring mathematics here.
Imagine a blind man standing at some point on a mountain who wants to reach the valley. Well, how do you think he can achieve that without seeing anything? To go with the gradient descent logic, the man must take a step wherever he feels a slope around him – the gradient. As he continues to move towards the slope – descent, he will reach the valley at some point.
Another thing to note here is that the more giant steps he takes, the faster he might reach – obviously, if he doesn’t take steps big enough to overshoot the valley. This is called the learning rate. The bigger the stride, the quicker your algorithm might find the minima; however, with a risk of missing the minima. This is a significant tradeoff to consider while choosing a suitable value of learning rate, but currently outside of the scope of this article.
Where Do Batch Size and Epoch Come into Play?
As you might already have guessed, the whole gradient descent process takes time and consumes a significant amount of energy. And if we have too much training data, it becomes impossible to pass it through the network all at once.
This is where batch size and epoch are handy. They let us divide the training data into small subsets and pass these subsets one by one to the neural network, making it more practical for the network to be trained. And since neural networks require the multiple passes of the complete dataset through the network, epoch lets us measure the total passes without confusing it with the batch size.
Let’s understand the terms in a greater depth in the following sections, along with why we need to care about them and calculate them.
What is Batch Size?
Suppose you have a dataset that contains a million training examples. Even if your neural network isn’t very complex (doesn’t have many hidden layers), a million training examples are still too much to process all together. It’s like putting a 100-ton weight on a Sedan. However, you still need to train the model with all those images; the more the data, the better your model will learn.
So, you cure that by dividing the dataset into several batches and then feeding the model one batch at a time. Batch size is the total number of training examples present in each of the batches. Note that the number of batches here does not equal the batch size. For example, if you divide the 1-million images dataset into ten batches, the batch size would be 100k.
What is Epoch?
As we discussed, most of the time, in deep learning, datasets are too big to be fed to the neural networks simultaneously. Hence, we divide data into batches and train each batch separately. So, one epoch is when all the training examples of the datasets are passed through the neural network once. This can also be interpreted as when all the batches are passed through the network once.
However, you might be wondering, why would someone pass all the training data through the network MORE than once? Making epoch an unnecessary thing. Well, let’s see.
Why Use More Than One?
Neural networks are complex. While it might be more than enough for the ML models to be trained on a dataset once, it’s mostly not enough for the deep networks. They are designed to catch even the most minor details the data contains, for which only a single epoch is seldom enough.
If we train the neural network on just a single epoch, we will get an underfitted model, which we obviously don’t want. Subsequent epochs enable the network to train better and hence fit the curve optimally. However, ensure you don’t set a very high value of epochs since it could also lead to overfitting.
Needless to say, there is no best-for-all solution when it comes to setting an optimal value for epochs. It’s again a tradeoff, just like in gradient descent’s case.
Batch Size Vs. Epoch – And How to Calculate Iterations
The batch size is the size of the subsets we make to feed the data to the network iteratively, while the epoch is the number of times the whole data, including all the batches, has passed through the neural network exactly once.
This brings us to the following feat – iterations. Iterations is a commonly used word in computer science, and its usage in deep learning is also quite similar. However, it’s important not to mix it up with batch size and epoch.
Iterations are essentially the total number of batches you need to perform one epoch in a neural network. Therefore, the term can be used interchangeably with the number of batches, but it’s recommended instead of writing no. of batches in neural networks.
So, how do we calculate the total number of iterations required for one epoch if we have a training dataset of 200,000 samples and a batch size of 10,000? We simply divide the total training samples by the batch size, which will get us the number of iterations it will take for one epoch – which is 20 in this case.
This means that to complete a single pass of the training dataset over the neural network will take 20 iterations! And there is hardly anybody who uses just one epoch. This makes you realize why all those deep neural networks take hours to train, even with the heavy GPU-enabled hardware and stuff.
Highly Recommended Next Articles
-
The Importance of Data Analysis in Research
Studying data is amongst the everyday chores of researchers. It’s not a big deal for them to go through hundreds of pages per day to extract useful information from it. However, recent
-
The Importance of Data Cleaning In Analytics Explained
Data cleansing has played an important role in the evolution of data management and analytics. It continues to evolve at a fast pace. Data cleansing is the act of going
-
The 5 Methods of Collecting Data Explained
Do you have to conduct research but do not know where to start? Does the thought of collecting data scare you? Well, data collection is not at all challenging. If
Conclusion
Even though the batch size and epoch are quite preliminary terms in deep learning, I’ve seen many beginners who don’t fully understand the difference between the terms and how it affects the neural networks. I don’t blame them since the terms are certainly somewhat similar, and if you don’t understand their purpose, it’s hard to remember what they do.
Throughout this article, we have gone through batch size and epoch in detail, looking at the crucial role they place in training deep neural networks and the difference between them. Moreover, we also looked at another term often used alongside them – iteration; and how to calculate it.
To conclude, batch size and epoch are both hyperparameters we set before training a deep neural network, but their purpose and usage differ significantly. Batch size, on the one hand, is used to reduce the total number of samples passed from the network at one instance, and epoch, on the other, is used to pass the complete data through the network multiple times to fit the data better.